[点晴永久免费OA]巨细!Python爬虫详解
当前位置:点晴教程→点晴OA办公管理信息系统
→『 经验分享&问题答疑 』
导读:爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者);它是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。 作者:潮汐 来源:Python 技术「ID: pythonall」  如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,他们沿着蜘蛛网抓取自己想要的猎物/数据。 01 爬虫的基本流程 02 网页的请求与响应网页的请求和响应方式是 Request 和 Response。
浏览器在接收 Response 后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收 Response 后,是要提取其中的有用数据。 1. 发起请求:Request请求的发起是使用 http 库向目标站点发起请求,即发送一个Request。 Request对象的作用是与客户端交互,收集客户端的 Form、Cookies、超链接,或者收集服务器端的环境变量。 Request 对象是从客户端向服务器发出请求,包括用户提交的信息以及客户端的一些信息。客户端可通过 HTML 表单或在网页地址后面提供参数的方法提交数据。 然后服务器通过 request 对象的相关方法来获取这些数据。request 的各种方法主要用来处理客户端浏览器提交的请求中的各项参数和选项。 Request 包含:请求 URL、请求头、请求体等。
一般做爬虫都会加上请求头。 例如:抓取百度网址的数据请求信息如下: 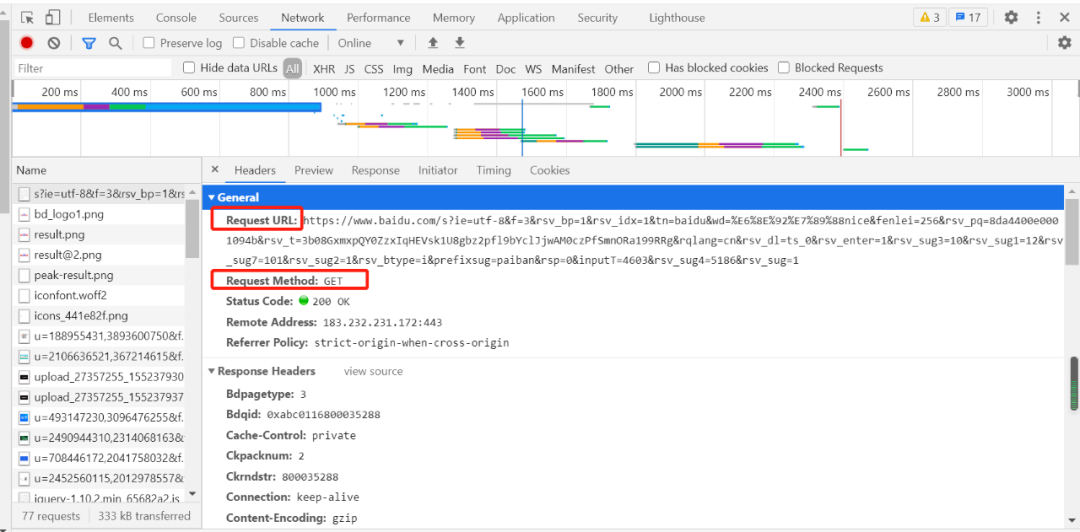 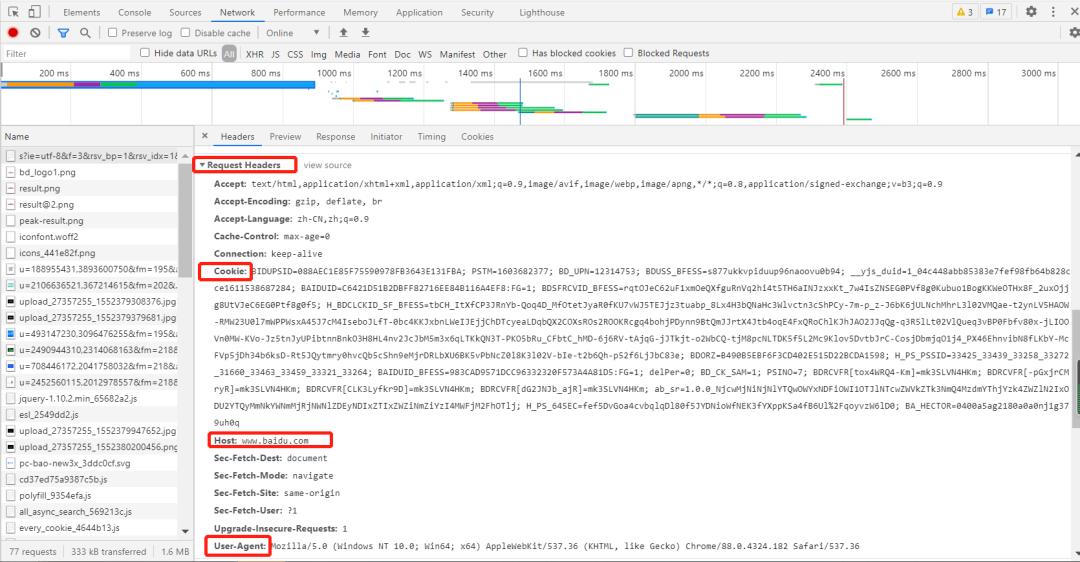 2. 获取响应内容爬虫程序在发送请求后,如果服务器能正常响应,则会得到一个Response,即响应。 Response 信息包含:html、json、图片、视频等,如果没报错则能看到网页的基本信息。例如:一个的获取网页响应内容程序如下: import requests request_headers={ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Cookie': 'BIDUPSID=088AEC1E85F75590978FB3643E131FBA; PSTM=1603682377; BD_UPN=12314753; BDUSS_BFESS=s877ukkvpiduup96naoovu0b94; __yjs_duid=1_04c448abb85383e7fef98fb64b828cce1611538687284; BAIDUID=C6421D51B2DBFF82716EE84B116A4EF8:FG=1; BDSFRCVID_BFESS=rqtOJeC62uF1xmOeQXfguRnVq2hi4t5TH6aINJzxxKt_7w4IsZNSEG0PVf8g0Kubuo1BogKKWeOTHx8F_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbCH_ItXfCP3JRnYb-Qoq4D_MfOtetJyaR0fKU7vWJ5TEJjz3tuabp_8Lx4H3bQNaHc3Wlvctn3cShPCy-7m-p_z-J6bK6jULNchMhrL3l02VMQae-t2ynLV5HAOW-RMW23U0l7mWPPWsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJEjjChDTcyeaLDqbQX2COXsROs2ROOKRcgq4bohjPDynn9BtQmJJrtX4Jtb4oqE4FxQRoChlKJhJAO2JJqQg-q3R5lLt02VlQueq3vBP0Fbfv80x-jLIOOVn0MW-KVo-Jz5tnJyUPibtnnBnkO3H8HL4nv2JcJbM5m3x6qLTKkQN3T-PKO5bRu_CFbtC_hMD-6j6RV-tAjqG-jJTkjt-o2WbCQ-tjM8pcNLTDK5f5L2Mc9Klov5DvtbJrC-CosjDbmjqO1j4_PX46EhnvibN8fLKbY-McFVp5jDh34b6ksD-Rt5JQytmry0hvcQb5cShn9eMjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2b6Qh-p52f6LjJbC83e; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33425_33439_33258_33272_31660_33463_33459_33321_33264; BAIDUID_BFESS=983CAD9571DCC96332320F573A4A81D5:FG=1; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BD_HOME=1; H_PS_645EC=0c49V2LWy0d6V4FbFplBYiy6xyUu88szhVpw2raoJDgdtE3AL0TxHMUUFPM; BA_HECTOR=0l05812h21248584dc1g38qhn0r; COOKIE_SESSION=1_0_8_3_3_9_0_0_7_3_0_1_5365_0_3_0_1614047800_0_1614047797%7C9%23418111_17_1611988660%7C5; BDSVRTM=1', 'Host':'www.baidu.com', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'} response = requests.get('https://www.baidu.com/s',params={'wd':'帅哥'},headers=request_headers) #params内部就是调用urlencode print(response.text) 以上内容输出的就是网页的基本信息,它包含 html、json、图片、视频等,如下图所示:  Response 响应后会返回一些响应信息,例下: 1)响应状态
2)Respone header
3)preview 是网页源代码最主要的部分,包含了请求资源的内容,如网页html、图片、二进制数据等 4)解析内容
5)保存数据爬取的数据以文件的形式保存在本地或者直接将抓取的内容保存在数据库中,数据库可以是 MySQL、Mongdb、Redis、Oracle 等…… 03 写在最后爬虫的总流程可以理解为:蜘蛛要抓某个猎物-->沿着蛛丝找到猎物-->吃到猎物;即爬取-->解析-->存储。 在爬取数据过程中所需参考工具如下:
04 总结今天的文章是对爬虫的原理做一个详解,希望对大家有帮助,同时也在后面的工作中奠定基础! 转自:https://cloud.tencent.com/developer/article/1815295 该文章在 2024/1/16 9:35:26 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886


